Hat die Kündigungsrate ein Potenzial, ihr Gewinn zu schmälern? Überholt die Kündigungskurve die der teuren Neukundengewinnung? Haben Sie Rückgewinnungsprogramme ausprobiert?
Wenn Sie sich mit dem Thema beschäftigt haben, haben Sie schon mit Sicherheit versucht, Gemeinsamkeiten bei Kündigungen zu erkennen und plausible Erklärungen für die Gründe zu finden. Möglicherweise haben Sie auf diesem Weg festgestellt, dass in einigen Ortsteilen ungewöhnlich viele Abgänge gab, oder dass es einen zeitlichen Zusammenhang mit Beschwerden gibt. Da der Umgang mit unzufriedenen Kunden zu optimieren nie verkehrt ist, bekommen die Betreuer eine zusätzliche Schulung und einen Vorrat an Amazon-Gutscheinen. Sie hoffen, dass Maßnahmen wirken und der Anlass an Relevanz verliert. Wenn der wahre Grund zu kündigen ein anderer ist, haben Sie wenig erreicht.
Die Krux ist, dass es meist nicht „den einen" Kündigungsgrund gibt. Ich kenne es von mir selbst: Es ist vielmehr eine Kombination von Gründen, die mich dazu bewegt, eine Versicherung, einen Stromanbieter oder eine Bank zu wechseln. Diese einmalige Konstellation bei meinen Kunden „per Hand" zu finden ist schwierig. Denn wir, Menschen, stoßen schnell an unseren Grenzen, wenn wir mehr als zwei bis drei Einflussfaktoren und ihre Zusammenhänge betrachten. Zum Glück beschäftigen sich Data Scientists schon lange mit der Thematik und verfügen über eine ganze Menge schlauer Algorithmen, die hinter dem Sammelbegriff „Predictive Analytics" stehen. Künstliche Intelligenz bedient sich den gleichen Verfahren, so dass die Grundprinzipien, die ich im Weiteren beschreibe, gleichermaßen auf viele KI-Systeme zutreffen.
Was ist „Predictive Analytics"?
Data Scientists treten oft wie moderne Schamanen auf. Sie führen einen Datentanz auf und nach einer Weile, in der sie unverständliche, aber klangvolle Worte von sich geben, prophezeien Sie, dass es in den folgenden 3 Monaten Kündigungen regnen wird. Sie sagen, dass Marta Meier und Huber Peters höchste Aufmerksamkeit benötigen, wenn wir sie als Kunden behalten wollen.

Wie kommen Sie darauf?
Kurze Antwort ist: Sie bringen dem Algorithmus bei, einen „Kündiger" von einem treuen Kunden zu unterscheiden. Data Scientists sprechen logischerweise nicht mit den Ahnen, sondern nutzen dafür Algorithmen aus dem Umfeld „Predictive Analytics" und „KI".
 Für eine lange Antwort brauche ich Erdbeeren und Tomaten.
Für eine lange Antwort brauche ich Erdbeeren und Tomaten.
Wie bringen Sie jemanden, der nie im Leben diese so etwas gesehen hat, sie ausschließlich nach ihrem Äußeren auseinanderzuhalten?
Sie benötigen dafür eine Menge beschrifteter Bilder von Rosen- und Schattengewächsen, damit „der Lehrling" sie erkennen lernt.
Die meisten Tomaten sind größer als Erdbeeren. Zusätzlich finden wir auf der Erdbeerhaut „Pünktchen" (die eigentliche Früchte), wobei Tomatenoberfläche glatt ist. In der Sprache von Data Scientists haben wir zwei Variablen identifiziert:
- Form
- „Pünktchen"
Jetzt geht es ans Sortieren. Alle großen kommen auf einen Stapel. Der Rest wird nach den „Pünktchen" auf der Haut aufgeteilt.
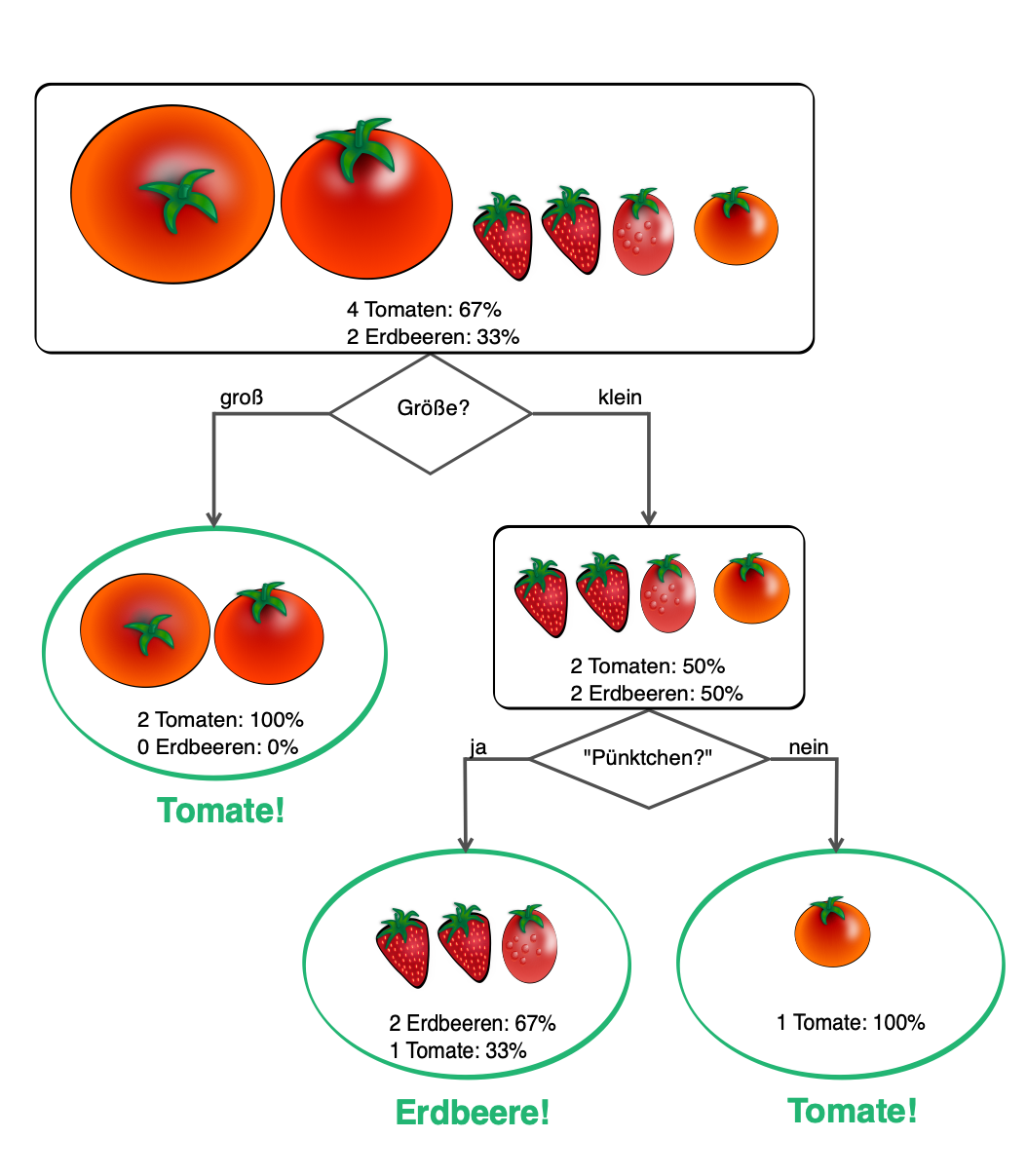
Nach einigen Durchläufen stellt der Algorithmus selbst fest, welche Variablen relevant sind, und arbeitet künftig damit, deswegen füttern Data Scientists das Programm mit möglichst vielen Daten. In unserem Beispiel bietet es sich an, die Form hinzuzunehmen, um die Qualität beim Sortieren zu erhöhen. Wenn die Erkennung zuverlässig funktioniert, gilt das Modell als trainiert und ist in der Lage, selbstständig Bilder zu identifizieren. Dabei wird stets angegeben, mit welcher Wahrscheinlichkeit eine Erdbeere oder eine Tomate erkannt wurde.
Genau so wird ein Modell für Kündigungserkennung erstellt. Es werden deutlich mehr Variablen genutzt: Kundenalter, Geschlecht, Vertragsalter, Nachzahlungen, Rückzahlungen, Mahnungen, Region, Produkt, Bonität, Verbrauch usw. Das Training findet auf Informationen aus der Vergangenheit statt: wobei bei jedem Datensatz klar ist, ob es sich um eine Erdbeere bzw. einen Kündiger handelt.
Ist die Erkennung zuverlässig, wird das Modell auf aktuelle Daten angewandt, so dass wir eine Liste der potenziell gefährdeten Kunden erhalten. Um Missverständnisse zu vermeiden: Es wird streng genommen nicht der Abgang prognostiziert. Der Algorithmus stellt fest, ob eine Person Merkmale eines Kündigers aufweist.
Jetzt ist es an der Zeit, Maßnahmen zu ergreifen: Die wertvollsten Kunden bekommen beispielsweise einen Anruf durch ein Call Agent, der nach ihrer Zufriedenheit fragt und ein verlockendes Angebot unterbreitet. Weitere erhalten ein Produktangebot per E-Mail. Dass hier DSGVO zu beachten ist, versteht sich von selbst. Damit ist eine Basis für ein Präventionsprogramm geschafft. Welche Zutaten zudem benötigt werden, um spürbare Ergebnisse zu erzielen, erfahren Sie im nächsten Abschnitt.
Rezept für erfolgreiche Kündigungsprävention
Ein Modell aufzusetzen und die erste Kampagne ins Leben zu rufen, reicht bei weitem nicht aus. Der Algorithmus benötigt regelmäßigen Training, die Präventionsmaßnahmen Anpassungen und Erfolgsmessungen, deswegen führt nur ein strukturiert und konsequent umgesetztes Kündigungspräventionsprogramm zum langfristigen Erfolg. Über die geheimen Erfolgszutaten spreche ich mit Peter Neckel, Leiter Customer Analytics bei Positiv Thinking Company.
Was ist Ihr Rezept für die erfolgreiche Kündigungsprävention? Gibt es eine Geheimzutat?
Mit einer Kündigerprognose versucht man, künftige potenzielle Kündigungen vorherzusagen. Mit klassischem Reporting gelingt das nicht, hierzu sind Verfahren aus dem Maschinellen Lernen und des Data Mining nötig.
Entscheidend für den Erfolg eines solchen Vorhabens sind meist jedoch andere, nichttechnische Faktoren: Das Spektrum reicht von der möglichst frühzeitigen crossfunktionalen Zusammenarbeit von Mitarbeitern aus Kundenservice, Vertrieb, Marketing, Produktmanagement und IT, über die gemeinsame Kampagnen- und Maßnahmenplanung bis hin zur Etablierung eines Regelkreises, in der die Kampagnenergebnisse zur Verbesserung der nächsten Kündigerprognose genutzt werden. Die erfolgreiche Umsetzung erzeugt hohen Abstimmungsbedarf, für den genug Projektzeit vorgesehen werden sollte.
Wie sieht eine Erfolgsmessung aus?
Erfolg kann sehr unterschiedlich definiert werden. Man springt allerdings in den meisten Fällen zu kurz, wenn man bereits die Sektkorken knallen lässt, sobald der Data Scientist meldet, ein Klassifikationsmodell zur Kündigerprognose mit hoher Genauigkeit trainiert zu haben.
Denn zwischen der Berechnung der Kündigungswahrscheinlichkeit pro Kunde und der erfolgreichen Kundenrückgewinnung liegt die Beantwortung zentraler Fragen: Welche der potenziellen Kündiger kann und will ich voraussichtlich mit welcher Maßnahme genau von einer geplanten Kündigung abhalten? Bei der Umsetzung geht es dann z.B. um die Festlegung von Kunden-Ansprachekanälen und -themen, Kontaktzeitpunkten, Kosten-/Nutzen-Rechnungen, Bildung von Kontrollgruppen, Art und Umfang der Datenerfassung bei der Kundenansprache etc.
Um am Ende der Evaluationsphase mit einer hohen Kundenrückgewinnungsquote belohnt zu werden, müssen die genannten Prozessschritte in jedem Einzelfall klug ausgestaltet und orchestriert werden.
Warum ist das Training des Modells so wichtig?
Das Training eines AI-Modells zur Kündigerprognose ist ein Baustein in einem vielschichtigen Prozess. Die Treffsicherheit eines Modells hängt dabei von vielen Faktoren ab, u.a. auch von der Qualität der zugrundeliegenden Daten.
Dabei gilt es, zwischen Datenaktualität und -menge abzuwägen: Einerseits benötigen viele Prognoseverfahren eine Mindestmenge an Trainingsdaten; zudem gleichen Daten aus mehreren Jahren Historie saisonale Schwankungen aus. Andererseits verlieren Daten massiv an Prognosekraft (manche Kundenverhaltensdaten sogar exponentiell) und damit an Wert, je älter sie sind. Daher sollten Modelle, die im Produktiveinsatz sind, regelmäßig überprüft und wenn nötig mit aktuellen Daten neu trainiert werden. In der Unternehmenspraxis unterbleibt das leider oft.
Sie sind im Data Science Bereich schon seit 15 Jahren erfolgreich unterwegs. Welche Fehler sind unbedingt zu vermeiden?
Unterschätzen Sie die Komplexität der Aufgabe nicht! Kündigungsprävention ist deutlich mehr als Data Science. In den meisten Unternehmen gibt es vor Beginn der Analysen keinen operativen Kundenrückgewinnungsprozess für Kunden, die zum Zeitpunkt der Ansprache noch gar nicht gekündigt haben. Dieser Prozess muss mit allen Beteiligten während des Projekts neu geschaffen und praktisch erprobt werden, mit allem, was dazu gehört: Neue Zuständigkeiten und Ergebnisverantwortung, abteilungsübergreifende Strukturen & Abläufe. Das ist keine Kleinigkeit, weil es massive Veränderungen in der Organisation und der Unternehmenskultur bedeutet. Auch, weil etwa vor Durchführung von Kundenrückgewinnungsaktionen zunächst gemeinsames Vertrauen in die Korrektheit von mit AI-Methoden erstellten Prognosen geschaffen werden muss. Nicht umsonst heißt es: „The hardest part of a successful transformation is the cultural piece".